如何用网站日志分析工具做seo网站分析?对于SEOer站长来说,网站日志文件的分析是每个SEOer站长的必修功课。网站日志文件分析,不仅能让SEOer站长时刻了解蜘蛛抓取网站的实时情况,并根据分析后的数据来不断提升网站优化质量度还能在一定程度上对网站今后优化的走势有一个预判。因此,网站日志文件的分析就尤为重要,那么,如何分析网站的日志文件?如何利用日志分析工具来分析网站日志就成为每位SEOer必会的一项技能。今天,小编木子就通过实例给大家分享一下网站日志文件的分析方法吧。
SEOer为什么要做网站日志文件分析?
首先,通过网站日志文件的分析,可以让我们比较准确的定位搜索引擎蜘蛛来爬行我们网站的次数,可以屏蔽伪蜘蛛(此类蜘蛛多以采集为主,会增加我们服务器的开销)点此识别Baiduspider真伪 ;
其次,通过分析网站日志,我们可以准确定位搜索引擎蜘蛛爬行的页面以及时间长短,我们可以依次有针对性的对我们的网站进行微调 ;
最后,http返回状态码,搜索引擎蜘蛛以及用户每访问我们的网站一次,服务器端都会产生类似301,404,200的状态吗,我们可以参照此类信息,对我们出现问题的网站进行简单的诊断,及时处理问题。
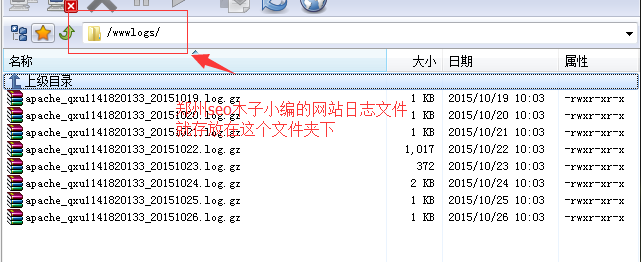
网站日志文件存放在什么地方?
一般的虚拟主机都提供日志文件,但是不同的虚拟主机系统会提供不同的LOG文件存储文件名,小编木子使用的是万网的虚拟主机,日志文件存储在wwwlogs文件夹下。当然,如果使用vps或者服务器的话,我们就可以将网站日志文件存放在任何自己想要的位置。
网站日志文件里面的记录怎么看?
首先,我们需要选择日期时间,来下载我们需要的网站日志文件。然后,将日志文件导入到网站日志分析工具中(网上的seo日志分析工具有很多,本案例中,木子小编使用的是光年SEO日志分析工具)。
原始访问日志每一行就是类似以下的记录:
123.125.71.21 - - [08/Jul/2015:01:06:51 +0800] "GET /jianjie HTTP/1.1" 200 6677 "-" "Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)" qxu1146370085.my3w.com text/html "/usr/home/qxu1146370085/htdocs/index.php" 483818
下面我们来说说这一行记录的意思:
123.125.71.21 这是访客(也可能是机器人)的IP
[08/Jul/2015:01:06:51 +0800]
这是访客访问该资源的时间(Date),+0800是该时间所对应的时区,即与格林威治时间相差+8个小时
GET /seojcyh HTTP/1.1
请求信息,包括请求方式、所请求的资源以及所使用的协议,该语句的意思就是以GET方式,按照HTTP/1.1协议获取网页/seojcyh,/seojcyh为网站上的某个页面。【http://seo.blogbus.wang/seojcyh】
200 6677
200为该请求返回的状态码(Http Code),不同的状态码代表不同的意思,具体请阅读 HTTP 状态代码;6677为此次请求所耗费的流量(Size in Bytes),单位为byte
qxu1146370085.my3w.com
为访客来源(Referer)。这一段是告诉我们访客是从哪里来到这一个网页。有可能是你的网站其他页,有可能是来自搜索引擎的搜索页等。通过这条来源信息,你可以揪出盗链者的网页。
Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html
为访客所使用的浏览器类型(Agent)
常见的网站日志中蜘蛛爬取返回代码的类型有哪些?
在蜘蛛爬取后会返回代码,通过查看贷款状态可以看到爬取结果,主要HTTP状态码有一下几类:
(1)200代码,表示蜘蛛爬取正常。
(2)304代码,表示自从上次抓取后,该内容没有更新。一般情况下,网站的图片经常会返回该值。
(3)404代码,访问的这个链接是错误链接。这个错误链接,一方面来自原本存在后来删除了网页,另一方面可能来自本来就不存在,但其他人外链了这么个死链接。
(4)302代码,表示临时重定向。
(5)301代码,表示永久重定向。
(6)500代码,表示程序有错。
如何分析网站日志中的内容都需要注意哪些信息?
1、注意那些被频繁访问的资源
如果在日志中,你发现某个资源(网页、图片和mp3等)被人频繁访问,那你应该注意该资源被用于何处了!如果这些请求的来源(Referer)不是你的网站或者为空,且状态码(Http Code)为200,说明你的这些资源很可能被人盗链了,通过 Referer 你可以查出盗链者的网址,这可能就是你的网站流量暴增的原因,你应该做好防盗链了。
2、注意那些你网站上不存在资源的请求
如果某些请求信息不是本站的资源,Http Code不是403就是404,但从名称分析,可能是保存数据库信息的文件,如果这些信息让别人拿走,那么攻击你的网站就轻松多了。发起这些请求的目的无非就是扫描你的网站漏洞,通过漫无目的地扫描下载这些已知的漏洞文件,很可能会发现你的网站某个漏洞哦!通过观察,可以发现,这些请求所使用的Agent 差不多都是Mozilla/4.0、Mozilla/5.0或者libwww-perl/等等非常规的浏览器类型,以上我提供的日志格式化工具已经集成了对这些请求的警报功能。我们可以通过禁止这些Agent的访问,来达到防止被扫描的目的,具体方法下面再介绍。
3、观察搜索引擎蜘蛛的来访情况
通过观察日志中的信息,你可以看出你的网站被蜘蛛访问的频率,进而可以看出你的网站是否被搜索引擎青睐,这些都是SEO所关心的问题吧。日志格式化工具已经集成了对搜索引擎蜘蛛的提示功能。常见搜索引擎的蜘蛛所使用的Agent列表如下:
Google蜘蛛 :Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)
Baidu蜘蛛 :Baiduspider+(+http://www.baidu.com/search/spider.htm)
微软Bing蜘蛛 :msnbot/2.0b (+http://search.msn.com/msnbot.htm)
Google Adsense蜘蛛 :Mediapartners-Google
有道蜘蛛 :Mozilla/5.0 (compatible; YoudaoBot/1.0; http://www.youdao.com/help/webmaster/spider/)
Soso搜搜博客蜘蛛 :Sosoblogspider+(+http://help.soso.com/soso-blog-spider.htm)
Sogou搜狗蜘蛛 :Sogou web spider/4.0(+http://www.sogou.com/docs/help/webmasters.htm#07)
Google图片搜索蜘蛛 :Googlebot-Image/1.0
Alexa蜘蛛 :ia_archiver (+http://www.alexa.com/site/help/webmasters)
4、观察访客行为(筛选黑客等异常行为并提前做好防范)
通过查看格式化后的日志,可以查看跟踪某个IP在某个时间段的一系列访问行为,单个 IP的访问记录越多,说明你的网站PV高,用户粘性好;如果单个IP的访问记录希希,你应该考虑如何将你的网站内容做得更加吸引人了。通过分析访客的行为,可以为你的网站建设提供有力的参考,哪些内容好,哪些内容不好,确定网站的发展方向;通过分析访客的行为,看看他们都干了些什么事,可以揣测访客的用意,及时揪出恶意用户。
以上就是今天,郑州SEO木子小编用实战案例给大家分享的分析网站日志文件的全过程。希望,对大家有所帮助。需要说明的是,网站日志文件的分析并不难,关键在于分析日志文件后,发现问题该怎样解决。今后,小编会给大家详细的讲解。同时也欢迎大家联系木子小编(QQ:194964241)就seo网站优化以及网络营销进行交流。
转载请注明出处。

 相关文章
相关文章
 精彩导读
精彩导读
 热门资讯
热门资讯 关注我们
关注我们
